APIを使う前に知っておきたい概要
ここではAPIの概要について説明します。C、C++のみならずPHP、Ruby、ActiveXを利用する場合もお読みください。
transactdのインターフェースの基本はCとC++のインターフェースからなります。その上に RubyやPHP Javaといったインターフェースが 構築されます。(現在用意されているのはC C++ Ruby PHP COM)
Cのインターフェースは tdclc_32_2_2.dll(32bit用 Windowsのみ) または tdclc_64_2_2.dll (64bit Windows) 、libtdclc_64.so.2.2.0(64bit Linux)の名前のライブラリで提供されます。 エクスポートされた関数はPSQL互換でPSQLからのマイグレーション を容易にできるようになっています。 このインターフェースの仕様の詳細はこのドキュメントでは述べません。
Cのインターフェースは、レコードイメージをフィールドの長さと型に応じてバイナリーフォーマットする必要があります。 これは、これからアプリケーションを作成するユーザーにとっては大きな負担となります。代わりにC++インターフェースを使用してください。
C++のインターフェースは、Cのインターフェースとは異なり、オブジェクト指向のわかりやすいインターフェースです。
RubyやPHPなどのインターフェースもC++のインターフェースとほぼ同じ名前で同様の機能が提供されます。 さらにC++ではより便利な コンビニエンスAPI が提供されます。
クラスの構成は継承関係を示すよりも、関連を示す方が理解しやすいためhas関係の関連図を示します。
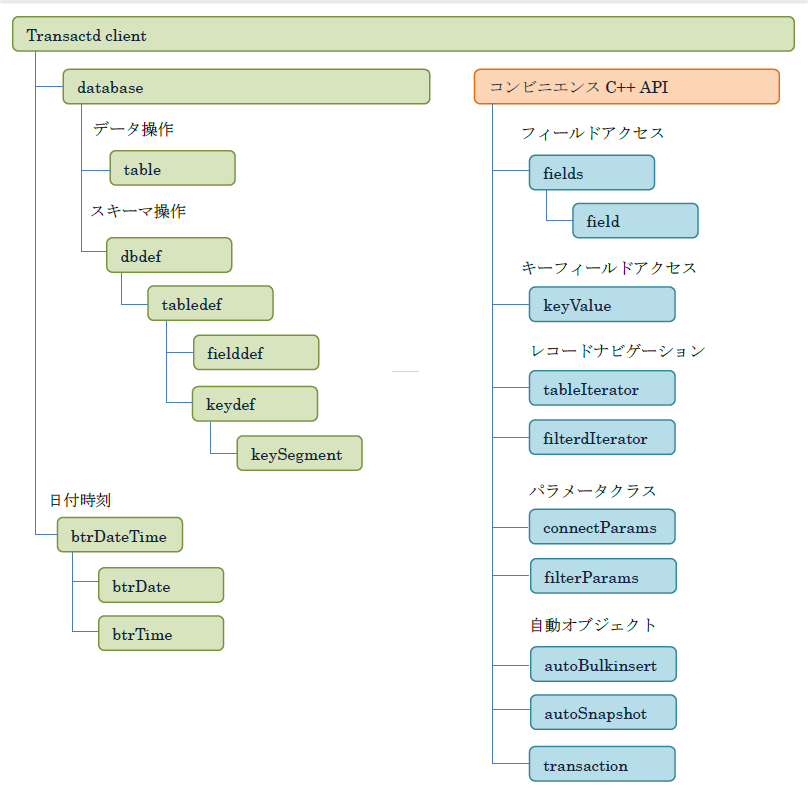
Version 2.0以降では、複数レコードの読み取りで結果セットを保持するrecordsetとrecordクラスおよびJoinやUnionを実行しrecordset に結合するactiveTableクラスが追加されています。
C++のインターフェースは(lib)tdclcppで始まるdll(Windows)またはso(Linux他)ファイルで提供されます。 Linuxではlibtdclcpp_64m.soをリンクして使用します。(64bit マルチバイトのみ対応)
Windowsではマルチバイト仕様 m とユニコード仕様 u また、64bit仕様 64 と32Bit仕様 32 の組み合わせの 4種類がファイルがあります。 4つの組み合わせのどれでアプリケーションをビルドするかでリンクする dllを変える必要があります。
例
Windowsでは作成されるアプリケーションのビルドオプションで TRDCL_AUTOLINK マクロを定義する と必要なdllを自動でリンクできます。 尚、一般的には文字コードの取り扱いが容易なユニコードを使用することを お奨めします。
PHPインターフェースはphp_transactd.soが提供します。インストールすると、 PHPのextension_dirに配置されます。また、php_transactd.soが提供するAPIをPHPのクラスにまとめたtransactd.phpがinclude_pathに配置されます。
transactd.phpはphp_transactd.soを通じC++インターフェースのso(dll)を呼び出します。
基本的なクラスとメソッドはC++APIとほぼ同様です。C++との違いについては、開発者ガイドを参照してください。
Rubyインターフェースはtransactd.soが提供します。Gemでインストールすると、 Gem専用のフォルダーにインストールされます。 transactd.soは内部でC++インターフェースのso(dll)を呼び出します。
基本的なクラスとメソッドはC++APIとほぼ同様です。C++との違いについては、開発者ガイドを参照してください。
COMインターフェースはtdclatl.dllが提供します。WindowsインストーラでTransactd Client and SDKをインストールすると %ProgramFiles%BizStation\tranasctd\binにインストールされます。 tdclatl.dllは内部でC++インターフェースのdllを呼び出します。
.NetからCOMインターフェースを使用する場合は最初に[参照設定]にCOMのtransactdコンポーネントを追加します。基本的なクラスとメソッドはC++APIとほぼ同様です。C++との違いについては、開発者ガイドを参照してください。
transactdにアクセスするにあたりサーバーカーソルという重要な概念を理解する必要があります。 データの読み取りにおいて、SQLでは複数の結果行ををローカルに取ってきて、各行をスクロールしながら処理していきます。 このスクロールの中で現在フォーカス(選択)している行(カレント行)をカーソルと呼んでいます。通常SQL による処理はクライアント側でのカーソルを使います。これをクライアントカーソルと呼びます。それに対 してtransactdのオペレーションは基本的にサーバーカーソルを使用します。サーバーカーソルは1行づつス クロールする際に、サーバー側で管理されるカレント行を移動していきます。たとえば、 nstable::seekNext()というメソッドは、サーバー管理された現在のカレント行を次の行に移動してその行をローカルに転送するという処理をしています。
サーバーサイドでは、SQLのjoinなど集合演算に相当する機能はありません。サーバーでのアクセスはすべて個別のテーブル単位です。 それらに相当する処理はすべてクライアントライブラリ(tdclcpp)内で行われます。
テーブルをオープンした直後はサーバーカーソルは存在しません。カーソルを確立するにはインデックスを使用する方法と、レコードの物理順を使用する方法の2つがあります。初めにインデックスを使ってカーソルを確立する方法を説明します。
インデックスを指定すると、各行はインデックス順に並んでいると考えてください。 インデックスを使う場合はnstable::seek系オペレーションを使用します。 nstable::seekFirst() nstable::seekLast()はそれぞれインデックス順に並べられた行の先頭、最後にカーソルを確立します。seek は事前に指定したインデックスフィールドの値でseekタイプに従がって見つかった行にカーソルを確立します。 seekのタイプには
の5つがあります。カーソルが確立されると、 nstable::seekPrev()、 nstable::seekNext()で1行づつ前後に移動できます。 各オペレーションの実行ステータスは nstable::stat()メソッドで読み出します。
サンプルコード レコードの読み取りと更新
カーソルが確立できるとtable::getFV系メソッドでその行のフィールドの値を読み取ることができます。 読み出す値の型に応じて table::getFVbyt() table::getFVint() table::getFVlng() table::getFV64() table::getFVflt() table::getFVdbl() table::getFVstr()などがあります。
フィールドの指定は、それぞれのメソッドの引数にフィールド番号(short)またはフィールド名(const _TCHAR*)で指定します。
値のセットは table::setFV(short index, int value)または table::setFV(const _TCHAR* fieldname, int value)のどちらかの関数で行います。 valueの型はそのほか組み込み型とconst _TCHAR* がオーバーロードされています。 値のセットは、読み取りオペレーションの前にインデックスの値を指定する時と、追加・更新オペレーシ ョンでフィールドの値をセットするときの両方で使用します。
読み出し、セットともにフィールドの指定は番号と名前のどちらでもできます。パフォーマンスを最大に したいときは番号を使うようにしてください。名前での指定は呼び出しごとに、名前から番号の検索が行われ パフォーマンスが悪くなります。
番号で指定し且つ、フィールドの追加などスキーマ変更に対して強いコードにするには、テーブルを開 いたあとで、フィールドを示す変数に名前から番号を検索した結果をキャッシュしておくようにします。 名前から番号の検索は table::fieldNumByName()メソッドで行うことができます。
フィールド番号をキャッシュする例 fdi_xxx変数にフィールド番号をキャッシュします
物理順はレコードが挿入された順番です。(ただし、mysqlのinnodbエンジンでは厳密な物理順は存在せず primaryキー順と同じ並びになります。) レコードの物理順によるオペレーションはstep系オペレーションを使用します。最初のカーソル確立は table::stepFirst() table::stepLast() の2つのみで、それぞれ物理順に並んだ行の先頭、最後にカーソルを確立します。移動は table::stepPrev()および table::stepNext()で行います。
サーバーカーソルは1行移動する度にネットワーク通信が発生するため、多くの行をまとめて読み取りたい 場合には効率の悪いことが あります。transactdでは1回の通信でまとめて複数行を取得するfind系オペレーションが用意されています。 findオペレーションではフィルターを指定することで読み取りたい行を選択します。フィルターの構文はSQL 文のwhere句によく似ています。
のように指定できます。(ただし、フィルターにはSQLに比べて制限があります。SQL文のwhere句と同等なものではありません。詳しくは table::setQuery() 関数 query クラスと基底クラスの queryBase を参照してください。) また、query では一回に取得する最大行数(limit)とフィルターにマッチしない行の最大数とし て最大スキップ行数(reject)も合わせて指定します。 フィルターを適用する読み取り範囲の先頭は、前記seek系オペレーションによって確立された現在のカーソ ル位置です。 範囲の最後は、指定したインデックスの最後のレコードになります。ただし、最大スキップ行数に1を指定し た場合は、最初のフィルターにマッチしない行の前の行が最後になります。パフォーマンスをよくするには、 テーブルの最後の行までスキャンされないように、最大スキップ行数に1を指定し検索範囲の最後を絞り込 みます。 取得した行を移動するにはfindPrev() findNext()を使用します。それぞれ、limitの最後に達する と、自動で次のlimitの行を取得し返します。プログラマーから見るとlimitは透過的で その値は何を指定しても得られる結果は同じです。ただし、パフォーマンスには違いが出てきます。
サンプルコード レコードのセットの読み取り
レコードの挿入はフィールドに値をセットし table::insert(bool ncc)メソッドを実行します。事前にカーソルが確立され ていた場合、挿入後のカーソル位置を元のままにする(No Currency Change)か挿入した行の位置にするかncc パラメータで指定することができます。
サンプルコード レコードの挿入
更新の対象行は現在のカーソル行になりますので予め更新したい行にカーソルを移動しておきます。 あとはレコードの挿入と同じように更新したいフィールドに新しい値をセットし table::update(eUpdateType type = changeCurrentCc)メソッドを実行 します。 もしインデックスフィールドを変更した場合は、更新後のカーソル位置を更新前と同じにするか更新後の位 置にするかtypeパラメータで指定できます。(更新前と同じ位置の行は厳密には存在しなくなっていますが、 table::seekPrev() table::seekNext()によって移動する先は正しいものとなります。)
また、typeパラメータに eUpdateType::changeInKey を指定すると nstable::keyNum で指定したキーを使ってレコードを移動し更新します。 これにより事前に更新したい行へ移動しておく必要がありません。但し、これを利用できるのは
サンプルコード レコードの読み取りと更新
削除の対象行は現在のカーソル行になりますので予め削除したい行にカーソルを移動しておきます。 あとはdel()メソッドを実行します。 table::del(bool inkey = false)を実行するとカーソル行は存在しなくなりますが、 table::seekPrev() table::seekNext() table::stepPrev() table::stepNext()によって削除した行前後に移動できます。
また、inkeyパラメータにtrueを指定すると nstable::keyNum で指定したキーを使ってレコードを移動し削除します。 これにより事前に削除したい行へ移動しておく必要がありません。但し、これを利用できるのは重複のないユニークキーである必要があります。
サンプルコード レコードの削除
トランザクションは nsdatabase::beginTrn() nsdatabase::endTrn() nsdatabase::abortTrn()関数でそれぞれ開始、 コミット、中止の処理ができます。beginTrn()の呼び出し以降に実行された、insert() update() del()よるすべての 変更を成功させるか、 または行わなかったことにするかendTrn()もしくabortTrn()の呼び出しで決定できます。
また、トランザクション内でカーソルの確立、移動を行うとそのレコードはロックされます。
ロックは、シングルレコードロックとマルチレコードロックがあります。 シングルレコードロックはそのテーブルの最後移動したレコードのみがロックされます。 マルチレコードロックはトランザクション内で読み出したすべてのレコードがロックされます。
ロックされたレコードを他のクライアントが読み取ろうとするとロックが解放されるかタイムアウトするまで 待たされるようになります。
他のクライアントへの影響を少なくするには、シングルレコードロックロック の使用を検討してください。どちらのロックを使用するかは nsdatabase::beginTrn()への引数で指定できます。 トランサクション内で更新されたレコードはシングルレコードロック、マルチレコードロックにかかわらず、 コミットされるまでロックされます。
サンプルコード トランザクション処理
トランザクションは、同じデータベース内であれば複数のテーブルにまたがって適用できます。
複数の更新処理をトランザクション内で行うと一般的にパフォーマンスは良くなります。しかし、長い時間 のかかるトランザクションはそのほかのクライアントの処理をブロックする恐れがありますのでなるべく短 い時間で完了するようにします。(mysqlのinnodbエンジンは完全な行ロックを提供しますのでPSQLのエ ンジンより並列実行性が高く、他のクライアントのオペレーションをブロックすることは少なくなっていま す。 PSQLのエンジンも行ロックを提供しますが、インデックスページはページロックのため、 更新や追加ではよりロック範囲が多くなります。 特に複数の行の追加は同じインデックスページに書き込むことが多く容易にブロックが発生します)
Version 2.0よりsetFilterによるフィルタリングされた複数レコードの読み取り結果を、配列をエミュレートしたrecordsetオブジェクトに まとめて受け取れるようになりました。また、その結果セットに別のテーブルの値をJoinやUnionすることもできます。 さらにrecordsetクラスは、結果セットに対するOrderByやGroupByといった処理もサポートします。 recordsetに結果を受け取る場合は、通常のtebleではなくactiveTableクラスを使用してアクセスします。
以下に簡単な例を示します。
1行目はactiveTableオブジェクトにdetabaseオブジェクトを渡して"user"テーブルとして初期化します。
2行目はフィルタリングするためのクエリーオブジェクトを生成します。
次に、selectで取得するフィールドをid, name, groupの3つを指定し、id が15000を取得するようにしています。 queryとactiveTableクラスのgettter setterメソッドの名前の省略が他のクラスとは異なり、setを省略しています。またほとんど のメソッドは、メソッドチェーンをサポートするために、*thisを返します。
4行目は、結果を受け取るrecordsetクラスのインスタンスを生成します。
activeTableで使用するindex番号と検索を開始するキー値(キー番号で指定されたキーのフィールドの値) を指定し、readメソッドにrecordsetとクエリーを渡して読み取ります。
recordsetから各行の読み出しは配列と同じように、[]演算子で取り出しできます。
各行はrowオブジェクトで["id"]のように[]演算子でidフィールドを取り出しできます。また、フィールド名でなく[1] のようにフィールド番号で取得することも可能です。
まず、文字コードには以下のものがあります。
文字列フィールドの値の文字コードはスキーマにて指定します。Transactdクライントは自動でクライアントプログラムで使用する文字コードに変換します。
クライアントプログラムで使用する文字コードは、テーブルやフィールドの名前などを引数に取る関数で使用する文字コードです。 クライアント側は、C++の場合WindowsとLinux・Mac、またUnicodeコンパイルとマルチバイトコンパイルなどの組み合わせによって変わってきます。 WindowsではUnicode、Linux・Macではutf-8が標準となっています。
サーバー側で設定された文字コードとはmy.cnfのcharset-serverで指定した文字ーコードです。transactd内部から発行される一部のSQL文はこの文字コードに変換する必要があります。
これらの各種文字コードの種類が異なる場合は変換が必要になります。 実行環境や、コンパイルオプションの組み合わせによってどのようにしたらよいかを示します。
|
C++クライアント |
項目 |
ターゲットサーバー | |
|---|---|---|---|
| Transactd | PSQL | ||
| tdclcpp_x_32u.dll tdclcpp_x_64u.dll (Windows UNICODE) | サーバー文字コードの設定 (my.cnf charset-server) | UTF8または漢字の使用可能なcharsetを指定します。 charset-server = utf8 | サーバーに指定するコードページはOSのコードページにしてください。サーバーOSのコードページとクライアントOSのコードページは同じである必要があります。 |
| tabledef::schemaCodePage | スキーマは任意のマルチバイト文字コードで作成できます。schemaCodePageはスキーマに使用するコードページを指定してください。 テーブル名やファイル名をセットする前に指定します。テーブル名やファイル名のセット関数を呼び出すと、内部でschemaCodePageに変換して保存します。 tabledef::schemaCodePage = CP_932; |
← | |
| 関数のURIパラメータ | 関数のURIパラメータはUNICODEで渡します。URIの送信はUTF8に変換されて行われます。 database::create(L"tdap://localhost/販売?dbfile=販売.bdf"); | 関数のURIパラメータはUNICODEで渡します。URIの送信はOSのコードページに変換されて行われます。 | |
| 関数のフィールド名パラメータ | 関数のフィールド名パラメータはUNICODEで渡します。フィールド名はUNICODE からスキーマのコードページに変換されて検索されます。 table::setFV(L"名前", L"akio"); |
← | |
| tdclcpp_x_32m.dll tdclcpp_x_64m.dll libtdclcpp_64m.so (WindowsマルチバイトLINUX他) | サーバー文字コードの設定 (my.cnf charset-server) | UTF8または漢字の使用可能なcharsetを指定します。 charset-server = utf8 | スキーマはサーバーに指定したコードページで作成してください。 |
| tabledef::schemaCodePage | スキーマはUTF8で作成してください。 schemaCodePageはUTF8を指定します。 tabledef::schemaCodePage = CP_UTF8; | schemaCodePageはサーバーに指定したコードページを指定してください。 | |
| 関数のURIパラメータ | 関数のURIパラメータはUTF8で渡します。URIの送信は変換せずに行われます。 database::create(u8"tdap://localhost/販売?dbfile=販売.bdf"); | 関数のURIパラメータはサーバーに指定したコードページで渡します。URIの送信は変換せずに行われます。 | |
| 関数のフィールド名パラメータ | 関数のフィールド名パラメータはUTF8で渡してください。フィールド名はUTF8同士で正しく検索できます。 table::setFV(u8"名前", "akio"); | 関数のフィールド名パラメータはサーバーに指定したコードページでで渡してください。フィールド名はサーバーに指定したコードページ同士で正しく検索できます。 | |
文字コードを正しく扱うにはまず、実行環境の文字コード(execCodepage)とベータベースに保存された文字列の文字コード(codepage)の2つがあることを意識します。 実行環境の文字コードはオペレーティングシステムと言語によりほぼ決まってきます。 windowsの多くの言語はutf16を主体とします。linuxの場合はutf8を主に使用します。 transactdの文字コード変換はすべてクライアント側で行われます。サーバー側での変換は一切ありません。
execCodepageは、char型の文字列のコードページが何であるかを示します。LINUX版はデフォルトでUTF-8です。 Windows版は、CP_ACPの値がデフォルトです。Windowsで、SetFV関数などで、フィールドの値をUTF-8で渡す場合は、事前に nsdatabase::setEexecCodepage() でCP_UTF8を指定しておく必要があります。 ワイド文字 wchar_t型のSetFV関数では、execCodepageが何であるかは関係ありません。
linuxでは libtdclcpp_64m.soはすべてマルチバイト文字セットとしてコンパイルされます。_TCHARマクロはchar型としてコンパイルされます。 また、execCodepageのデフォルトはGetACP()マクロが 常に utf8(コードページ 65001)を返すようになっています。 このコードページでなくたとえばcp932で処理したい場合は、 nsdatabase::setExecCodePage()を使ってexecCodepageを変更します。
次に、データベースの文字コード(codepage)は fielddef::charsetIndex()が参照されます。このcodepageとexecCodepageが異なる場合 文字コードの変換が行われます。windowsでの変換はosのWideCharToMultiByteとMultiByteToWideCharを使って行われます。 linuxはiconvを使って変換されます。linuxでは変換を高速に行うために、文字コードの組み合わせごとに変換ライブラリをオープンしてキャッシュしています。 デフォルトのキャッシュは mbcs utf16 utf8の3つの文字コードのすべての組み合わせの6つがされます。mbcsの文字コードはデフォルトで"SHIFT-JIS" が mbcswchrLinux.hのMBC_CHARSETNAMEマクロで指定されています。デフォルトのmbcsを変更する場合は、MBC_CHARSETNAMEを変更してコンパイルし直す必要があります。 また、複数のmbcsを同時に使用する場合は、mbcswchrLinux.h及びmbcswchrLinux.cppのコードにそれを追加するための変更を加える必要があります。
fielddefクラスのtype属性で指定できるフィールドタイプを説明します。 ここで説明するフィールドタイプのほとんどはTransactdからは問題なく使用できますが SQLからのアクセスにおいては、期待通りに読み取れないものがあります。 Transactdでは、フィールドのバイナリーフォーマッティングをクライント側で行っています。 TransactdでのアクセスだけでなくSQLからも正しく読み取れるようにするには、両方で 正しく読み取れる型を選択します。 MySQLのデータベースを使用する場合は、string, zstring, autoinc、integer、uinteger 、floatおよびmyが先頭に付くデータタイプを使って構築してください。MySQLのmoneyとdecimal型は現在のところtransactdは未対応です。
PSQLのデータベースを使用する場合は、myが先頭に付かない型を使用してください。 PSQLで、myの付いた型はキーフィールドには使用できません。使用するとテーブルの作成でエラーになります。
C++クライアントでは、フィールドにC++の組み込み型で値をセットすると 自動でそれぞれの型にフォーマットされます。
データタイプ対応表 も参照してください。
Transactdスキーマではフィールドの長さをすべてバイトで指定します。
しかしながら、MySQLのCHAR、VARCHAR型では文字数での指定のため変換が必要になります。 ここではその変換の計算方法について説明します。 最初に文字コードごとに違う1文字当たりのバイト数を lenByCharnum()関数を使って取得します。 CHARの場合長さは1文字当たりのバイト数 × 最大文字数がフィールドの長さになります。 VARCHARの場合は、文字の長さを表すバイトが1または2バイトが追加で必要になります。 1文字当たりのバイト数 × 最大文字数が255バイト以下の場合は1、それ以上は2バイトを 付加します。 また、 fielddef::setLenByCharnum()関数を使うと、文字数で長さを指定することができます。 その際、事前に fielddef::setCharsetIndex()関数で文字コードを、 fielddef::typeにフィールドタイプを 指定しておく必要があります。
Transactdクライントのオブジェクトはスレッド間での共有は安全ではありません。スレッドごとに 専用のオブジェクトを使用する場合は安全です。
Webサーバーアプリケーションで、複数のスレッドで処理を行う場合はスレッドごとに異なるdatabaseオブジェクトを 使用してください。
Webサーバーアプリケーションではサーバーとの接続のオーバーヘッドを減らすためにコネクションプール の使用を検討してください。コネクションプールにアクセスし利用するには pooledDbManager クラスを使用します。コネクションプールを使う例は以下のサンプルを参照してください。
サンプルコード コネクションプールを使う
Transactd SDK 2015年09月08日(火) 19時13分36秒


